
From Apache to lighttpd and back again
Reading the fascinating insights from cdbaby.com's Derek Sivers on switching from PHP to Ruby and back to PHP has encouraged me to blog about something I've been thinking of blogging for a while now: our departure from Apache to lighttpd as web server of choice for FanFooty during the last three months and our very recent flight back to Apache.
Apache was pretty much a default for our sites to begin with, as the A part of LAMP. However, we have had increasing problems with FanFooty scaling up to meet the demands of huge numbers of concurrent users. By far FanFooty's most popular pages are the live match fantasy scoring pages - for example the one for the Geelong v Collingwood game this weekend - which after many battle-hardening iterations have been reduced down to a flat HTML page which through AJAX calls a single comma-delimited text file every 30 seconds. No PHP, no mySQL, just flat text files.
Even this pared-down architecture was showing distinct signs of overloading on our one solitary server halfway through the 2007 AFL season, with frequent crashing during peak load times. I don't know exactly how many concurrent users we had, but each match day we were getting accessed by 12,000 unique browsers over the course of the day, so I would estimate that load on each live match fantasy scoring page would have been many thousands of requests for the exact same file every 30 seconds... for a couple of hours straight.
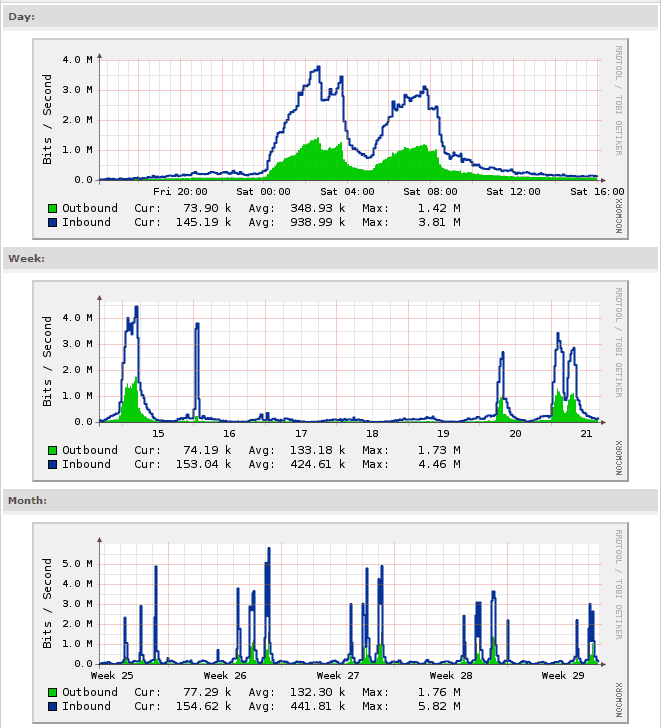 Seen at right, our traffic graphs were the same for every game: a smooth ramp up during each game culminating in a big spike at the end of each game as fantasy coaches checked the final scores. Some days there would be at least one game on continuously for eight straight hours, with three or four spikes.
Seen at right, our traffic graphs were the same for every game: a smooth ramp up during each game culminating in a big spike at the end of each game as fantasy coaches checked the final scores. Some days there would be at least one game on continuously for eight straight hours, with three or four spikes.
Something had to give. We examined the state of our server during those peak load times, and found that the main problem was that Apache was starting too many processes and running out of RAM. We tried doubling the RAM on our server, but that was an expensive process and not a long-term solution.
To cut a long story short: we heard of lighttpd, read some reviews, tested it, liked the concurrent user benchmarks we were getting on our box, tried it, and it worked a treat. The only teething problems came from having to rewrite Apache's .htaccess rules into lighttpd's mod_rewrite rules: regular expressions are tricky for a self-taught rube like me. Once it was up and running, all of our scaling problems went away, and in-game crashes almost disappeared.
I say almost, because lighttpd, for all of its speed and efficiency, has one glaring flaw: memory leaks. The hallmark of lighttpd is its low memory footprint compared to Apache, but to do that it has sacrificed a lot of Apache's management subroutines, one of the most important ones being how Apache handles the changeable rate of requests it handles over time. Through painful personal experience, I can say that lighttpd has serious problems with managing its memory footprint, in that it seems incapable of reducing its memory usage after a high load period. The lighttpd application seems to creep ever upwards in memory usage, ever so slightly over many hours, until it fills all available RAM and brings the server to a standstill. While the high load period is ongoing there is nothing better than lighttpd for handling thousands of concurrent users, especially for static content like text and picture files, but when the party's over lighttpd can't seem to shake off the hangover.
This is why we have switched back to Apache, now that the AFL football season is all but over. Having to manually restart the lighttpd application multiple times per day is a pain in the arse I don't want to have to deal with. I'm putting co-founder Tai on the task of building a remote monitoring application to run on our local boxes. We're even investigating the possibility of a "dual-boot" server, if you will, which would allow us to switch between Apache and lighttpd as traffic conditions dictate (EDIT: this link looks promising). We're trying to build Tinfinger with a similar reliance on flat text files (through a religious zeal for caching) so that when the TechCrunch traffic spikes hit then we'll be able to handle it with lighttpd.
I don't know that many Web applications would have similar traffic patterns and system architectures to FanFooty, but hopefully the above is helpful to someone who is in the position I was in three months ago and looks for guidance online about what to do in the face of massively spiky traffic problems.
Apache was pretty much a default for our sites to begin with, as the A part of LAMP. However, we have had increasing problems with FanFooty scaling up to meet the demands of huge numbers of concurrent users. By far FanFooty's most popular pages are the live match fantasy scoring pages - for example the one for the Geelong v Collingwood game this weekend - which after many battle-hardening iterations have been reduced down to a flat HTML page which through AJAX calls a single comma-delimited text file every 30 seconds. No PHP, no mySQL, just flat text files.
Even this pared-down architecture was showing distinct signs of overloading on our one solitary server halfway through the 2007 AFL season, with frequent crashing during peak load times. I don't know exactly how many concurrent users we had, but each match day we were getting accessed by 12,000 unique browsers over the course of the day, so I would estimate that load on each live match fantasy scoring page would have been many thousands of requests for the exact same file every 30 seconds... for a couple of hours straight.
Seen at right, our traffic graphs were the same for every game: a smooth ramp up during each game culminating in a big spike at the end of each game as fantasy coaches checked the final scores. Some days there would be at least one game on continuously for eight straight hours, with three or four spikes.Something had to give. We examined the state of our server during those peak load times, and found that the main problem was that Apache was starting too many processes and running out of RAM. We tried doubling the RAM on our server, but that was an expensive process and not a long-term solution.
To cut a long story short: we heard of lighttpd, read some reviews, tested it, liked the concurrent user benchmarks we were getting on our box, tried it, and it worked a treat. The only teething problems came from having to rewrite Apache's .htaccess rules into lighttpd's mod_rewrite rules: regular expressions are tricky for a self-taught rube like me. Once it was up and running, all of our scaling problems went away, and in-game crashes almost disappeared.
I say almost, because lighttpd, for all of its speed and efficiency, has one glaring flaw: memory leaks. The hallmark of lighttpd is its low memory footprint compared to Apache, but to do that it has sacrificed a lot of Apache's management subroutines, one of the most important ones being how Apache handles the changeable rate of requests it handles over time. Through painful personal experience, I can say that lighttpd has serious problems with managing its memory footprint, in that it seems incapable of reducing its memory usage after a high load period. The lighttpd application seems to creep ever upwards in memory usage, ever so slightly over many hours, until it fills all available RAM and brings the server to a standstill. While the high load period is ongoing there is nothing better than lighttpd for handling thousands of concurrent users, especially for static content like text and picture files, but when the party's over lighttpd can't seem to shake off the hangover.
This is why we have switched back to Apache, now that the AFL football season is all but over. Having to manually restart the lighttpd application multiple times per day is a pain in the arse I don't want to have to deal with. I'm putting co-founder Tai on the task of building a remote monitoring application to run on our local boxes. We're even investigating the possibility of a "dual-boot" server, if you will, which would allow us to switch between Apache and lighttpd as traffic conditions dictate (EDIT: this link looks promising). We're trying to build Tinfinger with a similar reliance on flat text files (through a religious zeal for caching) so that when the TechCrunch traffic spikes hit then we'll be able to handle it with lighttpd.
I don't know that many Web applications would have similar traffic patterns and system architectures to FanFooty, but hopefully the above is helpful to someone who is in the position I was in three months ago and looks for guidance online about what to do in the face of massively spiky traffic problems.
posted by Paul Montgomery | 1:13 am
|
11 comments
![]()